The importance of data consolidation – whatever you call it
Back to BlogWe all love an acronym, don’t we? Especially if they have three letters! SCV, SSV, CDP, MDM… in the world of data, these TLAs roam as freely and happily as wildebeest do the Serengeti.
Many of them live a long life and undertake marathon migrations, whether that migration is to the Masai Mara or the shiny new cloud server. Others fall prey to crocodiles, transformation projects, and new technology.
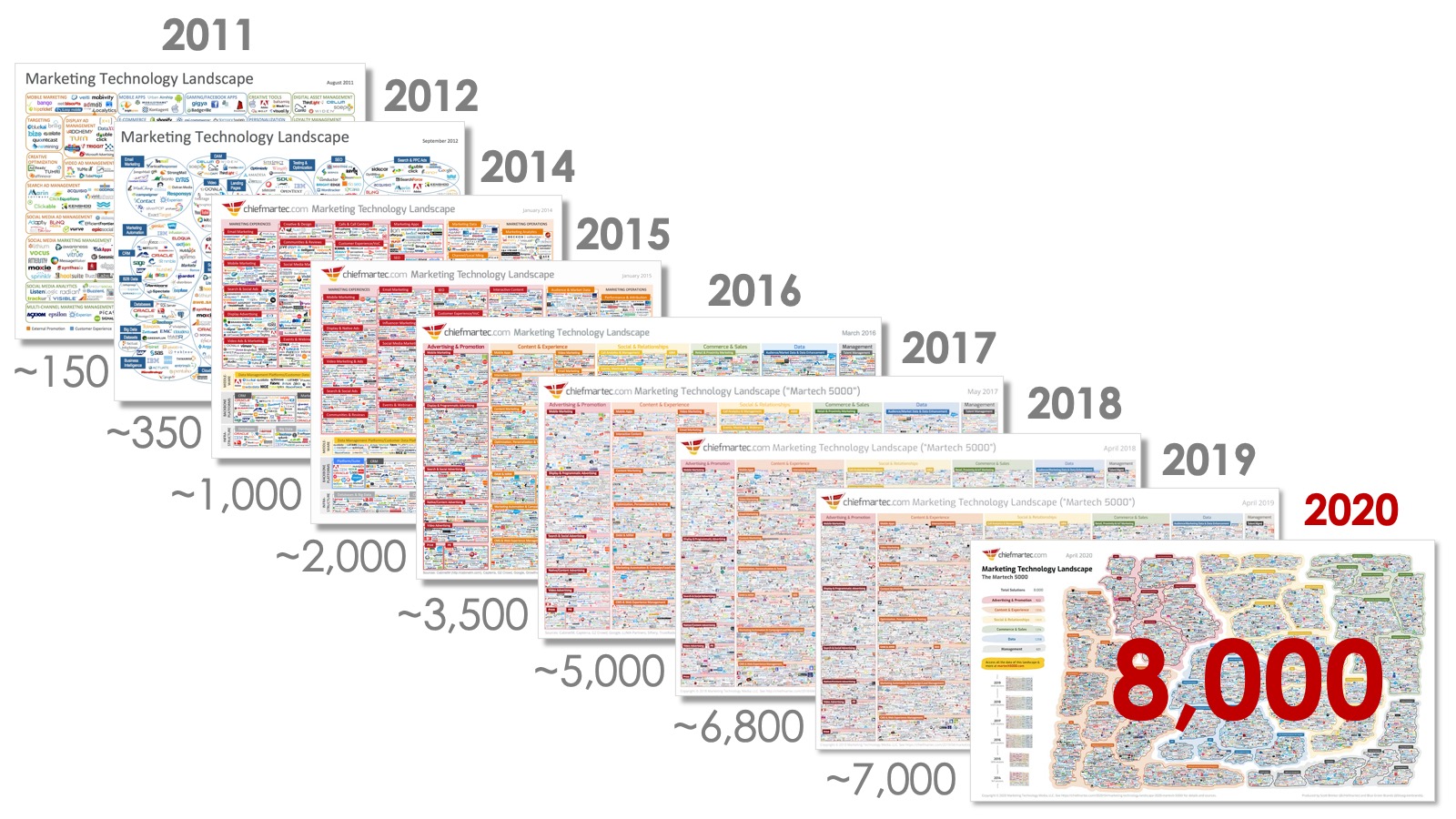
Wildlife comparisons aside, the development and evolution of the data environment grows exponentially each year. An easy place to see the effect of this is Scott Brinker’s chief martech annual landscape diagram. If you want a poster for your wall, then take a look at the diagram here. We wouldn’t recommend the dad jokes on the same site though – you’ve been warned!
{kind=link}
Why is data consolidation important?
Amongst all this change, one thing holds consistent and true – the need to visualise, process, and action data from multiple disparate systems in a single, all-encompassing place. It’s the (dare I say it) holistic, 360-degree view we all hear about in countless presentations… but you can understand why we hear about it so often. It’s vital.
For any organisation wanting to communicate with their customers, members, or supporters, or to provide a service that shows a complete appreciation of all touchpoints and interactions, the ability to recognise the same person across different systems (or even within the same system) is paramount.

Typical disparate data source types explained
This is the case whether you refer to this element of data management as part of an SCV (Single Customer View), SSV (Single Supporter View), CDP (Customer Data Platform), MDM (Master Data Management) or any other acronym you care to throw into the mix.
Some of the typical types of data brought into such views can be seen in this infographic. Note that, for now, no mention is made of by which channel, where or how this data is being collected.
Generally, that doesn’t change the process and rigour that should be employed in consolidating this information. Anonymous online data, however, requires a different approach to data which contains elements of personal identification.
As well as the ability to view behavioural data that will form a key outcome of a consolidation project, a further crucial element which should be realised is the reconciliation, aggregation and presentation of overall consent and suppression information relating to each contact record.
Understanding how data sources relate to each other
With several different data capture points or third-party suppression flags all potentially feeding into disparate systems, with the ability for changes to consent to be made against any one of these at any time, it’s important to have a full appreciation of how these relate to (and supersede) each other over time.
Depending on how organisation consents have been set up and collected, the way they’re collated to a single contact level could be done in different ways. For example, is an email opt-out collected against an animal rehoming system applied to the entire organisation or just the rehoming element?
Clearly, this depends on the wording and presentation of the consent capture process itself and is required to ensure compliance with GDPR is maintained.
And, of course, if third-party suppressions have been applied to (some or all) disparate systems then ensuring these form part of the process to flag any single contact appropriately should be a key part of the initial single view project. Once created, tagging third-party data to the resulting master records – rather, than the individual disparate systems – gives a more efficient and cost-effective way to supplement organisation-wide data.
How to consolidate traditional data
So, just how do we go about bringing these entities together, and are we limited to doing that only for people? Well, to answer the second point, no it isn’t just limited to people. However, you might not be surprised that reconciling the individual people within and across systems is the most common form amongst what we might term “traditional” data.
What do we mean by “traditional”? Well, in general, it would relate to good old names and postal addresses, also extending to telephone numbers and email addresses. Importantly though, when looking to identify an individual, it’s the name that’s key.
On top of that, it’s also common to establish common entities around households or addresses. And when we refer to a household, it’s important to ascertain what people may mean by that. Whilst a full name and address might identify an individual, and the address alone identifies… well, the address, what is it that makes a household?
Typically, this may be seen as the surname within an address. Although, it’s obvious what challenges that brings with shared housing or multi-surname residences of any kind. In the case of household matching, it’s probably the element that’s least likely to ever be truly correct, with some element of compromise needed one way or the other around how individuals within an address might be defined as a household.
The resulting “household” element can, therefore, render different results for different clients, projects and purposes.
How to consolidate digital data
Of course, entity resolution doesn’t have to stop with people and buildings. We’ve seen the process undertaken with animals (which brings its own challenges) and vehicles (which can be made easier using the vehicle identification number and allows different owners of the vehicle to be identified, along with colour changes and different registration plates).
Naturally in the digital world, we also see data being brought together through all manner of other identifiers. Importantly here, unless assumptions are being made, it’s crucial to ensure the consolidation of data from digital sources with offline sources is done with a level of authentication in the former.
It’s usual practice to hold online and offline data unlinked until such a time that some data is obtained from the online source to confirm an identity – for example, name and email address. At this point, any online and offline data sharing this identification key can be joined as a single entity and the true behaviour of an individual across the range of their activities (known and anonymous) becomes truly known.
Sticking with the digital world, many platforms use email address as a primary key on the system. This can simplify some things. But if we think about how that data might then be used downstream as a contributing feed in a data consolidation project, then we can start to think about some of the elements to deal with around this data.
For example, just because an email address only exists once doesn’t mean an individual person is only in that system once. They may have had multiple email addresses over time and registered on more than one occasion. And it’s important to be able to recognise these potential duplicate individuals as one person. Whether that’s possible also depends on what other data has been captured – a topic that links nicely to another blog of ours on data capture and governance.
How Wood for Trees can help with your data consolidation
If you can’t see the wood for the trees and need assistance with your data consolidation, or want to reap the benefits of data-driven reporting, don’t worry – help is at hand!
Check out our SCV/SSV whitepaper where we go into more detail on these topics and discuss some of the key considerations that should be made, plus techniques used to ensure the best outcome of an entity resolution project. Alternatively, why not have a read of our latest non-profit annual report and State of the Sector reports to discover the latest insights on data and trends.
Finally, if you’d like to find out more about our services and how we can help you unlock the power of your data, contact our team today to learn more.